Using Ingest actions in Splunk to export to non AWS S3 and how to import the data back from non AWS…
In this article you will see how you can use Ingest Actions in splunk to redirect data into S3-compatible storage. And how to retrieve it…


Using Ingest actions in Splunk to export to non AWS S3 and how to import the data back from non AWS S3
In this article you will see how you can use Ingest Actions in splunk to redirect data into S3-compatible storage. And how to retrieve it back from S3 into the splunk index.
Wait you might say, there is a AWS Add-On which is capable of ingesting from S3 you might say ? Yes and no….
It only is compatible to AWS S3 implementations, so the UI elements are restricted to AWS stuff.
So I had to develop my own. How ? HEC !
HEC ? … HTTP Event Collector
If you just want the script, go ahead, skip my walkthrough and learning path and get what you searched for, down below you can find the script
So now for the people who are willing to read throug my thought process.
Back story
A bit of a back story, you see if you do work with an API which is practical to implement into the REST API Modular Input from BaboonBones this is easy, but if you are not able to do so, you have to write you own script to get the data.
But you want it also in splunk, so how ? yeah you create an HTTP Event Collector, you can create basically an API token to post data right into the index queue and hope for the best.
No you have to format it in a specific way, ok you can just send the event field, but that is no fun.
What you really want to do is to send an event with all the original information you expect it to have, just when you would have collected it through the universal forwarder sooo:
- time
- source
- sourcetype
- host
- event
Now you have context.
So I knew that I can ingest data through an HEC, so I need to figure out how to connect to S3 and retrieve the data, and first check if this is at all usable data to work with, what splunk exports onto the S3 bucket.
But first lets get some data to go from the index queue out to the S3 bucket.
Configure Ingest actions to route data to S3 destination
Starting with the destination, you can configure it on the indexer manager, or on a search head connected, I assume you have the correct permissions going forward.
- So you select Settings > Ingest Actions under DATA
- Now you select Destinations
- You Add a Destination
- Now enter a unique name for the destination, I call it like s3-$sourcetype-$usecase
- Enter your S3 Endpoint URL, just type it in, the Dropdown is not a restriction, it states it also there that you can enter anything
- Enter your S3 Bucket, Folder (I set it to the name of the destination)
- Enter your Access ID und Secret Key
- Check with Test connection.

Please make sure under Advanced Options to disable Compression and enable the JSON format, so you can read it properly

So you now have a Destination.
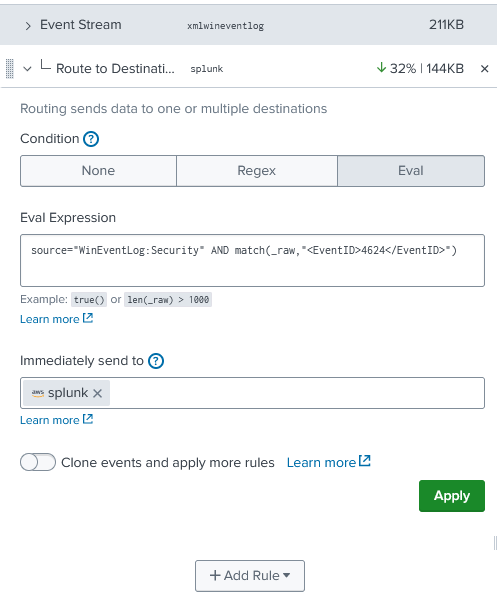
Now go into Rulesets, click Add Rule
- Give it a name, I did also like s3-$sourcetype-$usecase
- Then select the sourcetype you would like to intercept
- Select a sample size to design the filter rule
- Click on Apply
- Then add a rule “Route to Destination”
- Select EVAL and create a rule like
source="WinEventLog:Security" AND match(_raw,"<EventID>4624</EventID>")- Now remove “Default Destination”
- Select your specified new Destination for S3
- Your are done, now all Events matching that rule are now setup to be redirect to S3 and not ingested

Ingesting back into splunk
So now have a look onto S3 and view the files created.
As you see that out of luck your json files are just lists of event data formatted in a specific format.

Which format? when you read carefully you see that the data is right formatted like the object a HEC expects when posted onto it.
Sooooo lets begin and have fun!
// Btw. this looks easy now but it took a whole day to figure out
First I used python, because splunk is python and I may implement into a custom add-on.
So for working with with S3 on python AWS provides the boto3 module through pip, In my case I used conda but pip is fine.
I give you the complete list here because the rest are just modules you need anyway, no magic to unpack here
conda install boto3, requestsConnect to S3 with boto3
First you need to import boto3, duh. Then you connect an s3 resource and get your bucket selected
import boto3
s3 = boto3.resource('s3', endpoint_url='https://s3.example.com', aws_access_key_id='ADBCDEF', aws_secret_access_key='GHIJKLMNOP')
bucket = s3.Bucket('YOURBUCKET')You remember I have saved my data into a folder, but s3 does not understand folder, it understands prefixes .. path prefixes. So now on to getting you files from s3 loaded into python.
There is a object called objects on the Bucket object, it understands the .all() method and the .filter() method. to filter for any information we need yes, the filter method and our prefix.
bucket.objects.filter(Prefix='s3-$sourcetype-$usecase')This will give you every file in that prefix. We simply need to foreach it retrieve the json file and send it onto splunk, easy!
You might want to stop here, unfortunately boto3 or the S3 specification does not just stream you data into a variable, you need to specifically download it, but not save it, here is the catch ! SpooledTemporaryFile a function inside of tempfile. To use it you need to import tempfile and right now you can also import json and requests.
You need to specify how many bytes you are allowing it to save into memory before falling back to disk to save it, and that is 1MB, since I saw that the file are not really get bigger than that.
import requests
import tempfile
import json
#[...]
for object in bucket.objects.filter(Prefix='s3-$sourcetype-$usecase'):
data = tempfile.SpooledTemporaryFile(max_size=1000000)Now you have a place to save the data into memory, to now retrieve it you need one of the two functions, download_file or download_fileobj.
download_file expect you to save it into a path, we do not want that.
download_fileobj does exactly what we want, it downloads the file as an object into an object.
bucket.download_fileobj(object.key, data)Now hooray we have the data, so we see that the data is json, so we load it and foreach over the items in the json list.
We know that we can just post it onto the HEC, so also lets do that. Keep in mind that we need to define the authorization header for splunk
headers = {'Authorization': 'Splunk dd4680f4-bd33-426e-9ba6-f7ceff5761cd'}
events = json.loads(data.read())
for event in events:
requests.post(headers=headers, url='https://splunk.example.com', json=event)If we now execute that we see….
Nothing…
As I found out after working through the SpooledTemporaryFile docs I found that since it is a datastream I need to set the handler back to the front, because we wrote into it it was at the back with no data behind the last byte.
We do that with:
data.seek(0)Thats it, now it works, let us check


Eureka, it works, now we can import that data into splunk as we need it, so we can redirect data not needed away into s3 and retrieve it when we need it.
Soo there is still something more to keep in mind. When now ingesting through the HEC, the event just looks like it comes from the original source, because the source is in the event data and we have not touched it.
moving forward you will see that it lands directly back again in s3, so we need to differentiate between data coming from the original source and the HEC.
So I do this, do identify the data and the file and bucket and so on it came from:
event['source'] = object.keyThe key by the way is the filename of the object you currently have retrieved.
To now finally have the complete script you can go ahead
import boto3
import requests
import tempfile
import json
s3_endpoint = 's3.example.com'
s3_bucket = 'bucket'
s3_prefix = 's3-xmlwineventlog-event4568'
s3_access_key = 'ABDEFG'
s3_secret_key = 'HIJKLMNOP'
splunk_server = 'splunk.example.com'
splunk_token = 'dd4680f4-bd33-426e-9ba6-f7ceff5761cd'
headers = {'Authorization': 'Splunk ' + splunk_token}
s3 = boto3.resource('s3', endpoint_url=s3_endpoint, aws_access_key_id=s3_access_key, aws_secret_access_key=s3_secret_key)
bucket = s3.Bucket(s3_bucket)
for object in bucket.objects.filter(Prefix=s3_prefix):
data = tempfile.SpooledTemporaryFile(max_size=1000000)
data.seek(0)
bucket.download_fileobj(object.key, data)
events = json.loads(data.read())
data.close()
for event in events:
event['source'] = object.key
requests.post(headers=headers, url=splunk_server, json=event)
In the next post on this topic I will go ahead and will show an optimized version of a splunk modular input

